Two common Bayesian point estimators are the posterior mean and the posterior mode.
The posterior mode is the most likely value of the parameter given the data. It is the highest point in the posterior pdf. (The value, y, that maximizes P(y | data)). With uninformative priors, the posterior mode is frequently the same as the MLE.
The posterior mean is the expected value of the parameter given the data. E(y | data)
The posterior mode is useful when the parameter itself is your interest. For example, when measuring the fraction of voters who support candidate x, the posterior mode is the most likely fraction after you did your survey.
The posterior mean is useful when you want to predict the future based on the parameter. For example, the probability that an individual voter will support candidate x is the posterior mean.
Saturday, May 11, 2013
Friday, May 10, 2013
Visualizing why the determinant changes sign on column swap
If a matrix is broken into columns, the determinant of a matrix can be visualized as the volume enclosed by those vectors. Ask A Mathematician/Ask a Physicist had a very nice post explaining this. However, it was not clear to me why the volume changes signs when you interchange the vectors. It seems to me that:
Is the same parallelepiped as:
So, they have the same volume. But they do not have the same determinant. So, something is lacking in my intuition about determinants and volumes.
As a first step to understanding this aspect of determinants, I worked out the proof that swapping two vectors negates the determinant for the specific example of the determinant of a two-dimensional matrix, keeping track of the geometric intuition at each step.
For a two dimensional matrix, the determinant is the signed area of the enclosed parallelogram.

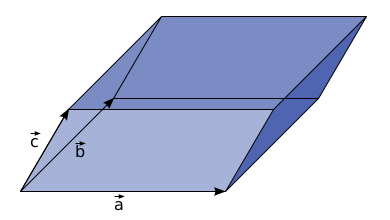 |
| Parallelepiped with one set of labels (image from the Ask A Mathematician article) |
 |
| Changing the labels doesn't change the parallelepiped |
So, they have the same volume. But they do not have the same determinant. So, something is lacking in my intuition about determinants and volumes.
As a first step to understanding this aspect of determinants, I worked out the proof that swapping two vectors negates the determinant for the specific example of the determinant of a two-dimensional matrix, keeping track of the geometric intuition at each step.
For a two dimensional matrix, the determinant is the signed area of the enclosed parallelogram.
{kind=link}
Subscribe to:
Posts (Atom)